In 1998 Brin and Page, then both PhD. candidates in the Computer Science Department at Stanford, created an algorithm for ranking webpages. This ranking method, which they called PageRank, became the heart of the successful and well-known search engine Google. The instant success of Google led Brin and Page each to take a leave of absence from Stanford to focus on their company. Now billionaires, they attribute much of Google's success to their PageRank algorithm.
The fundamental idea behind PageRank is the notion that each hyperlink is a recommendation, an endorsement of one page for another. Thus, the World Wide Web is a giant recommendation system where webpages vote for other pages by linking to them. Rather than simply counting the number of inlinks to a page and using this number to rank webpages by the number of votes they get, Brin and Page created a more sophisticated voting system. A page gets a high PageRank if it has recommendations in the form of inlinks from other highly ranked pages. This simple idea has had powerful, far-reaching impact on web search. Brin and Page and Google were some of the first to see the power inherent in the hyperlink structure of the Web. Since then, the field of link analysis, studying the hyperlink structure of the Web to improve web search has exploded. In fact, every major search engine today uses some type of link analysis.
Prior to link analysis, search engines relied on traditional methods for ranking webpages. These traditional methods used only page content to retrieve pages relevant to a search query. While content is important and is still analyzed by search engines, adding link analysis was a major improvement in the quality of the ranked results returned to the user. Spamming makes this clear. Search engines that use only content to return results to users are easily spammed. Spammers, who often have financial and business interests tied up in their webpages, intentionally try to deceive search engines into giving them an unjustly high rank so that their pages appear toward the top of the results list. Since spammers have complete control over the content of their pages, they can imbed meta-tags and keywords into the HTML that search engines may use to determine the content of a page. However, the text that appears on the page may be quite different. When link analysis is employed these spammers are less effective because spammers have little or no control over which pages inlink to theirs.
Google's PageRank algorithm, though mathematically elegant and very powerful,
is very easy to understand. The first step to understanding PageRank is to
view the Web as a giant graph. Each webpage is a node in the graph and each
hyperlink is a directed link connecting two nodes.
The figure above is a graphical
representation of the Web, but since there are so many pages the view gets
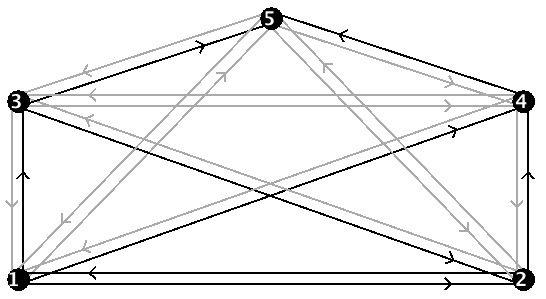
easily obscured. Instead, let's consider a much smaller web, a web with only
five webpages as depicted below; here all black links are active and gray links are inactive, in other words, not part of the network. Notice, for instance, that webpage 5 has
inlinks from webpages 3 and 4 but has no outlinks. Similary, webpage 2 has
an inlink from and an outlink to webpage 1.
(You will need the most recent version of the Java Console installed and enabled to be able to view this Java applet http://java.com/en/download/index.jsp)
Activities to follow so read on!
We will be using this applet often in later sections of this module. For now, we focus on just two parts of the applet: the graph at the top of the page and the section labeled "Adjacency Matrix" in the center bottom of the page. Click on links in the applet graph to create a graph that looks just like the graph above. When you use your mouse to click on a gray link it becomes black to signal that it is active.
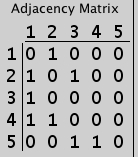
Every graph also has a corresponding mathematical representation that enables powerful mathematical analysis. The mathematical representation is called a matrix, which is a table of numbers showing which pages link to which other pages. Notice that the graph above creates the matrix below. The 1 in the second row and first column (i.e., the (2,1)-entry of the matrix) means that there is a link from webpage 1 to webpage 2 in the graph above.
Check that the adjacency matrix below matches the graph above.
Now remember Brin and Page's thesis for their PageRank algorithm: A webpage is important and gets a high PageRank if it has inlinks (gets lots of votes) from other highly ranked pages. One way to find the PageRank for each page is to think about a random surfer. This random surfer bounces along the Web following the hyperlink structure of the Web. Whenever he arrives at a page, he randomly selects a hyperlink on the current webpage to visit. He continues this process indefinitely. If we count the number of times he visits each page, the pages with the greatest number of visits are the most important pages because the random surfer keeps getting referred back to those pages by other pages. In fact, this is exactly how PageRank is understood and one method for its calculation. The idea behind Google's PageRank is to let a random surfer take a random walk on the Web's graph and then observe the frequency with which he visits each page. More important (i.e., more frequently visited) pages appear at the top of the results page for a query to the Google search engine.