Image Compression:
How Math Led to the JPEG2000 Standard
Compression in a Nutshell
The Goal of Image Compression
When we save a digital image as a file on a camera or a web server, we are essentially saving it as a long string of bits (zeros and ones). Each pixel in the image is comprised of one byte and each byte is built from 8 bits. If the image has dimensions M x N pixels, then we need MN bytes or 8MN bits to store the image. There are 256 different bytes and each has its own base 2 (bit) representation. Each of these representations are 8 bits long. So for a web browser or camera to display a stored image, it must have the string of bits in addition to the dictionary that describes the bit representation of each byte.
The idea of compression is very simple - we simply change the bit representation of each byte with the hope that the new dictionary yields a shorter string of bits needed to store the image. Unlike the ASCII representation of each byte, our new dictionary might use variable length bit representations. In fact, in 1952, David Huffman made the following observation:
Rather than use the same number of bits to represent each character, why not use a short bit stream for characters that appear often in an image and a longer bit stream for characters that appear infrequently in the image?
Huffman Coding
Huffman's simple idea was to identify pixels that occur frequently in an image and assign them short bit representations. Pixels that occur infrequently in an image are assigned long bit representations. We can better understand this idea if we look at an example of Huffman coding:
Suppose we want to store the word sassafras to disk. Recall from the Image Basics section, each letter in the word is assigned an ASCII number so the word sassafras may well be the first row of a digital image. In fact, the table below gives ASCII and bit representations for each of the letters in the word.
| Letter | | ASCII | | Binary | | Frequency | | Relative Frequency |
| s | | 115 | | 01110011 | | 4 | | 4/9 |
| a | | 97 | | 01100001 | | 3 | | 1/3 |
| f | | 102 | | 01100110 | | 1 | | 1/9 |
| r | | 114 | | 01110010 | | 1 | | 1/9 |
The word sassafras is built from 9 characters each requiring 8 bits. Thus we need 9*8 = 72 bits to store the word. Here is the word in bits:
| 01110011 | 01100001 | 01110011 | 01110011 | 01100001 | 01100110 | 01110010 | 01100001 | 01110011 |
| s | a | s | s | a | f | r | a | s | |
Huffman Algorithm
Step 1.
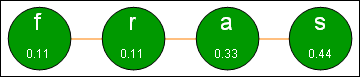
The basic Huffman coding algorithm is very easy to understand. You first sort the unique characters by relative frequency, smallest to largest. We put each of these characters and their relative frequencies in nodes connected by branches as illustrated below:
| |
|
|
| |
|
The four characters in sassafras, sorted by relative frequencies.
|
Step 2.
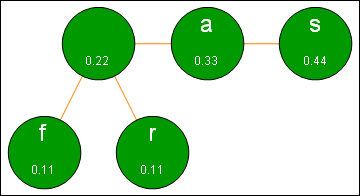
We now take the two leftmost nodes and add their frequencies to obtain .22. We create a new node with relative frequency .22 that has two children - the f and r nodes. We complete the step by sorting the top level nodes. The process is illustrated in the graphic below:
| |
|
|
| |
|
Step 2 in the Huffman process.
|
Step 3.
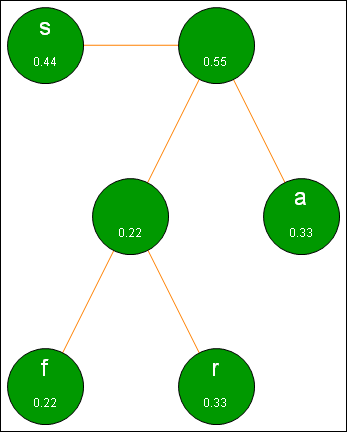
The third step is identical to the second - we add the relative frequencies of the two leftmost nodes and create a new node that has two children. We sort the top level nodes (note this time the new node has the larger frequency so it moves to the right). The process is illustrated in the graphic below:
| |
|
|
| |
|
Step 3 in the Huffman process.
|
Step 4.
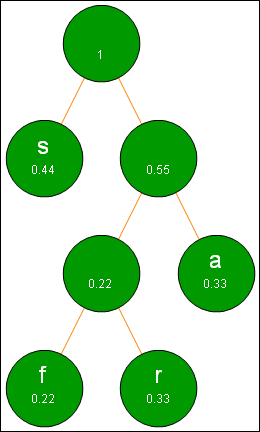
We continue the algorithm by essentially repeating the last two steps. Note that this time the new node has frequency 1. This frequency indicates that we are done creating new nodes.
| |
|
|
| |
|
Step 4 in the Huffman process.
|
Step 5.
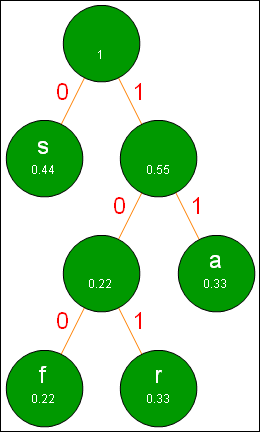
The final step in Huffman coding is to label all branches connecting nodes. Branches with positive slopes are labeled with 0 and branches with negative slopes are labeled with 0. The result is a completed Huffman Tree.
| |
|
|
| |
|
Step 5 in the Huffman process.
|
We can now read the new bit representation for each character from the Huffman tree. We start at the top node and create the new representation by gathering 0's and 1's as we proceed to the desired character. For example, instead of 01110011 for a bit representation, we use simply 0. The table below gives all new bit representations for the letters in sassafras.
| Letter | | Binary | Huffman |
| s | | 01110011 | 000 |
| a | | 01100001 | 011 |
| f | | 01100110 | 100 |
| r | | 01110010 | 101 |
We can write sassafras using the Huffman codes for each letter. We have:
| 0 | 11 | 0 | 0 | 11 | 100 | 101 | 11 | 0 |
| s | a | s | s | a | f | r | a | s | |
The new bit representation for sassafras requires only 16 bits as opposed to the original 72 bits. This is a savings of over 75%! We typically represent the compression rate in bits per pixel (bpp). Since we need 16 bits to represent sassafras and there are 9 letters in the word, the compression is 16/9 = 1.77bpp. This means that on average, each pixel requires 1.77 bits of storage space.
Inverting the Process
It is straightforward to invert a bit stream constructed from Huffman codes and determine the original input. The key observation is that every character node on the Huffman tree is a terminal branch. Since there can be no subsequent branches on character nodes, we are guaranteed that there will be no redundancy in the new bit representations for each character. Thus, if we have the dictionary AND the Huffman coded bit stream, we can determine the original characters.
As an example, consider the Huffman dictionary and bit stream below:
| Letter | | Huffman |
| s | | 00 |
| i | | 1111 |
| m | | 100 |
| p | | 101 |
Bitstream: 100110011001110110111
We start with the 1. Since no character is represented by 1, we consider 10. Again no character is represented by 10 so we proceed to 100. The dictionary yields an m for this bit sequence. Next comes a 11 (i) and 0 (s), 0 (s), 11 (i), 0 (s), 0 (s), 11 (i), 101 (p), 101 (p), 11 (i) so that the stream represents the word mississippi.
Huffman Coding and Digital Images
It is a bit of a sales job to only consider short words such as sassafras or mississippi. The range of byte values for a digital image can certainly go from 0 to 255 and in this case drawing the tree is impractical. We can still compute the Huffman codes.
Consider the image at right. It is 512 x 768 pixels for a total of 512*768 = 393,216 pixels or 393,216*8 = 3,145,728 bits. It turns out that all 256 grayscale intensities appear in the image. If we compute the Huffman codes for this image, then we find we can compress the storage size and use 3,033,236 bits or about 7.714bpp. This value hardly represents a significant savings!
What went wrong? The fact that all 256 pixel intensities appeared in the image forced the Huffman process to form the maximum number of levels (there were only four levels in our Huffman tree for sassafras) and that made most new bit representations only modestly shorter than the original ones.
The lesson to learn here is that while Huffman codes produce a savings when applied directly to an image, it will work much better if the image consists of fewer distinct intensities. What researchers have learned is that transforming an image to a different setting where the resulting output is comprised of significantly fewer pixel intensities dramatically increases the compression potential of Huffman coding (or other coding methods). That's where wavelets come in!
While the naive Huffman coding outlined above is not used in compression algorithms, it is a useful tool to understand the basic idea of image compression. The interested reader might wish to consult The Data Compression Book.