Image Compression:
How Math Led to the JPEG2000 Standard
Wavelet Transformations
Introduction/History
The term wavelet is relatively new in mathematics. While much of the companion theory that is used in wavelet analysis dates back to the 19th century, most researchers would agree that modern research in wavelet theory can be traced to the 1984 paper by French physicists Jean Morlet and Alexander Grossman and the foundational work on multiresolution analysis of Yves Meyer and Stephane Mallat in 1992 and 1989, respectively. Ingrid Daubechies constructed wavelet functions in 1988 and 1993 papers that give rise to all of the discrete wavelet transformations that are described on this web site. A wonderful description of the history of wavelets can be found in the book by Barbara Burke Hubbard.
Research on the topic and applications exploded in the 1990's. Much of the research in the 1990's focused on the applications of the discrete wavelet transformation and some of that work obviously led to the incorporation of the discrete wavelet transformation in the JPEG2000 Image Compression Standard. Some applications of wavelets (other than image compression) are:
- FBI fingerprint storage
- Edge detection in images
- Image morphing
- Image watermarking
- Signal denoising
(check out the web site Brahms at the piano)
- Detection of epileptic seizures
- Seismic data analysis
- Estimation of probability density functions
- Modeling of time series
- Numerical solutions to partial differential equatioms
What is a Discrete Wavelet Transformation?
A discrete wavelet transformation, like all linear transformations, can be represented as a matrix. Most transformation matrices share common properties:
- Block structure: an N x N wavelet matrix (with N even) is built from two blocks of size N/2 x N. The top block, when multiplied with a length N input vector, produces a list of N/2 weighted averages of the input values. The bottom block, when multiplied with a length N input vector, produces a list of differences that can be combined with the weighted averages to reconstruct the original input values.
- Cyclic rows: The top block is built from a (short) list of numbers. These numbers are placed in the top row of the top block and each subsequent row is obtained by rotating the previous row two units right. The list of L numbers, when dotted with a list of L input values, creates a weighted average of the L inputs. The bottom block is built in the same way but with a different list of numbers. In some cases, the list used for the bottom block is constructed from the list used for the top block. This list of M numbers, when dotted with a list of M input values, creates a measure of how those M values change. The list of values that make up the bottom block must sum to 0.
- Inverse Structure: The inverse of a wavelet matrix should be the transpose of a wavelet matrix. In some cases the wavelet matrix is constructed so that it is orthogonal. In this case, its inverse is its transpose. In other cases, two lists are used to create wavelet matrix W and the inverse of W is the transpose of matrix U where U is constructed from two lists of numbers.
Example Transformation Matrix
Here is an example of a wavelet matrix:
W = \left[\matrix{
3/4 & 1/4 & -1/8 & 0 & 0 & 0 & -1/8 & 1/4 \\
-1/8 & 1/4 & 3/4 & 1/4 & -1/8 & 0 & 0 & 0 \\
0 & 0 & -1/8 & 1/4 & 3/4 & 1/4 & -1/8 & 0 \\
-1/8 & 0 & 0 & 0 & -1/8 & 1/4 & 3/4 & 1/4 \\
-1/2 & 1 & -1/2 & 0 & 0 & 0 & 0 & 0 \\
0 & 0 & -1/2 & 1 & -1/2 & 0 & 0 & 0 \\
0 & 0 & 0 & 0 & -1/2 & 1 & -1/2 & 0 \\
-1/2 & 0 & 0 & 0 & 0 & 0 & -1/2 & 1
}\right]
The top half of the 8 x 8 matrix is constructed from the numbers -1/8, 1/4, 3/4, 1/4, -1/8. These numbers sum to 1 and represent a weighted average when dotted with five generic values. For example, if the input is (1,2,3,4,5), then the dot product is -5/8 + 1/2 + 9/4 + 1 - 5/8 = 3. The bottom half of the matrix is constructed from the list -1/2, 1, -1/2. These values sum to zero and readers who have had a course in numerical methods recognize this list as one used to approximate second derivatives. Here is the transpose of the inverse of W:
U = \left[ \matrix{
1 & 1/2 & 0 & 0 & 0 & 0 & 0 & 1/2 \\
0 & 1/2 & 1 & 1/2 & 0 & 0 & 0 & 0 \\
0 & 0 & 0 & 1/2 & 1 & 1/2 & 0 & 0 \\
0 & 0 & 0 & 0 & 0 & 1/2 & 1 & 1/2 \\
-1/4 & 3/4 & -1/4 & -1/8 & 0 & 0 & 0 & -1/8 \\
0 & -1/8 & -1/4 & 3/4 & -1/4 & -1/8 & 0 & 0 \\
0 & 0 & 0 & -1/8 & -1/4 & 3/4 & -1/4 & -1/8 \\
-1/8 & -1/4 & 0 & 0 & 0 & -1/8 & -1/4 & 3/4
}\right]
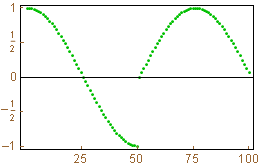
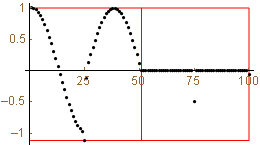
Notice that the list that generates the top (bottom) of U is related to the list that generates the bottom (top) of W. Below is a plot of a vector of length 100 and the wavelet transformation of the vector (we create an analog of W of size 100 x 100 to perform the transformation).
| |
|
|
|
|
|
| |
|
|
|
|
The wavelet transformation of the vector.
|
The second graph shows the two parts of the transformation. The first 50 components is a weighted average of the original input while the second portion is differences needed to combine with the averages to recover the original input.
Interpreting the Wavelet Transformation
The wavelet transformation above clearly consists of two portions. The first 50 components of the output is a weighted average of the input values. The last 50 components are differences needed to combine with the averages to recover the original input. Since the data are relatively smooth, the differences are near zero. There is one jump in the data and you should note that the differences portion of the transform clearly identifies this jump. Here you can see why the differences portion of the transformation is so valuable in applications - it tells us how the input data are behaving - big values indicates a change in the original data while values near zero tells us that there is little or now change in the original data.
Note also that the jump in the original data only affects a few values in each portion of the transformation. For this reason, the wavelet transformation is called a local transformation. Other transformations used in signal and image processing, such as the Fast Fourier Transformation and the Discrete Cosine Transformation are not local - if a value is perturbed in the original input, the result affects the entire output of the FFT and DCT. The ability to localize change in input data is a huge advantage of the wavelet transformation over other transformation in many applications.
What's in Store?
You have learned the very basics about discrete wavelet transformations on this page. To get a deeper understanding of wavelet transformations, please have a look at the subsection on the Haar Wavelet Transformation - the HWT is very easy to understand and we use it to motivate two-dimensional wavelet transformations that are used for image processing. The remaining two subsections discuss more advanced wavelet transformations and the wavelet transformations used in the JPEG2000 Image Compression Standard.