Discrete Fourier Transform
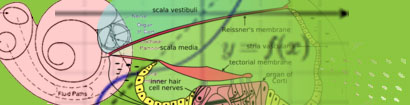
Most people are already familiar with the a different example of the concept of spectrum, because the audio player on your computer has this functionality. These players (usually) have the option to show a graphic equalizer or audio analyzer, which gives a graphical representation of the amount of energy in each of several frequency bands. The CI speech processor needs to perform that same operation – separate the signal into various frequency bands so that different parts of the cochlea can be appropriately stimulated. Note, however, that the theoretical description provided by Equation (2) requires that we know the time signal out to positive and negative infinity. So we need to find a way to apply this theory to our audio problem.
The next step in finding a computable solution to this problem is
to acknowledge two “facts” that
result from our objective of decomposing an audio signal: (1) Our signal
of interest covers only a finite period of time, and (2) because sound signals
of interest have no simple mathematical description, we will need to approximate
our integral using some numerical technique. The easiest way to incorporate
both these requirements (as well as the fact that our speech processor will
be a digital device) is to assume that instead of a continuous signal X(t),
we have a discretely measured signal, where we take N
measurement, denoted x_0,\dots,x_{N-1},
, where the measurements
are equally spaced in time. We define the Discrete Fourier Transform (DFT) by
X_k = \sum^{N-1}_{n=0} x_n e^{-i2\pi(\frac{kn}{N})}, \qquad k=0,\dots,N-1.
(4)
Again, this computation uses complex numbers. Each of the Xk
represents an amplitude and phase associated with a sinusoid. If we superposition
those sinusoidal waves, we can recreate the time signal at the sampled points.
To recover the original signal, the Inverse Discrete Fourier Transform (IDFT)
is given by
x_n = \frac{1}{N}\sum^{N-1}_{k=0} X_k e^{i2\pi(\frac{kn}{N})}, \qquad n=0,\dots,N-1.
(5)
Within the resolution of the discrete sampling, the DFT is
able to decompose the signal into its frequency components, though some aliasing
effects may occur if the signal has energy at too high of a frequency. For
example, if we were recording X values at a rate of 1,000 samples per second
(sampling frequency 1,000Hz), then the portion of the signal whose frequency
is below 500Hz will be accurately represent, while that portion of the signal
above 500Hz will create some distortion in the resultant signal and would
not be recovered by the IDFT. This sampling frequency requirement is described
by the Nyquist-Shannon sampling theorem (Shannon, 1949).
Now consider the computational requirements of a DFT. In
addition to computing the exponential, the real work is in the summation.
For each, we must add up N things,
while k ranges from 0 to N - 1.
So to compute the full DFT requires N2 additions.
Mathematician use the notation 0(N2) to
show this complexity. Note that IDFT is also 0(N2).
The implication for usage is that if you double the number of sample points,
the computation goes up by a factor of 4. If you take 10 times as many samples,
the work goes up by a factor of 100.
The range of human hearing is such that the upper limit
of detectable frequency is around 20,000Hz, though a high frequency of 8,000Hz
might be sufficient for most spoken communication. These high frequencies
require a lot of sample points. For instance, if our total measurement interval
is T = 0.01 seconds, to capture the sound at 20,000 Hz, one would need a
sampling frequency of 40,000Hz, which yields
N=(0.001)(40,000)=400.
One might imagine that to achieve a smaller number of samples, we can look at a shorter period of time, so that we can sample at a high rate, but without too many sample points. However, if the overall length of the sample determines the lowest frequency that is represented
(f_0\approx \frac{0.5}{0.01}=50 \mbox{Hz}).
Because we must preserve the low frequency, we cannot reduce the time window significantly.
So we don’t have a means to make N to be small. Additionally, in our application, it is very important that the computation be done quickly. We cannot allow any significant delay between when the sound is made and when it is sent to the cochlea. (You have all watched movies where the sound track is a little off, and the people speaking in the movie are not in sync with the voiced words. It is annoying to us. Imagine how difficult it might be if you are trying to use lip-reading to augment the understanding you are getting from the CI.) So if the problem can’t be made smaller, but we need to be fast, then we better find an efficient algorithm.